
I was in vCenter the other day and noticed that one of my virtual machines had the following message/warning:
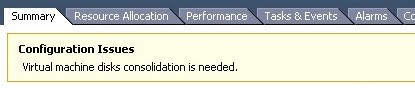
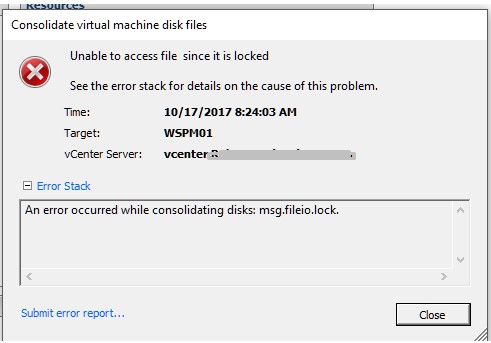
It was weird. I thought to myself, I’m the only one that has access to this vSphere environment and I haven’t taken any snapshots of this particular VM recently, so what could be the problem. I went to snapshot manager and didn’t see any snapshots listed which was odd (come to find out the snapshot DB was corrupt). I then went to ‘Snapshot Manager > Consolidate, to see if I could consolidate the VM’s after confirming there were snapshot files in the datastore (4 of them). Upon trying to consolidate the VM, it failed with the following error:
Error Occurred While Consolidating disks msg.fileio.lock.
Version: ESXi 5.5
My initial thought was hmmm…
Then I thought about what might be creating VM snapshots and of course that would be the image based backup solution that I run which is NetBackup. I head over to my NetBackup appliance and notice that there are failures for this particular VM. So I assume that the file(s) is locked by NetBackup.
To confirm that, I went into the hostd.log file on the host that it was sitting on and start reviewing the logs. Of course it says it can’t have access to the disk yet it doesn’t show me who’s locking it.
After Googling around I didn’t find much information or success on getting these VM files unlocked.
I tried finding the lock using these helpful KB’s.
https://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=2136521
https://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=10051
All I received back was an odd error which yielded no results on my Google search. After trying to figure out what I needed to do I thought, let me see if I can vMotion this to another machine and see if I can unlock these file(s) that way.
vMotion was a success, but the following consolidation effort still failed. My next thought was to shutdown the VM and the Netbackup Appliance. But before I did that, I thought that may not be the best option. Because if I shut down the VM, and it still has a lock on the file, then I’ll be stuck unable to power it back on.
So I basically was nervous to do a Storage vMotion to help release the lock so I punted to GSS (VMware Support). After initial troubleshooting these were the following steps that we laid out for a solution.
From GSS:
- We confirmed that the snapshot database is corrupt. This is why snapshot manager is not showing any active snapshots.
- We confirmed that the current snapshot chain and its data is consistent. The VM and its snapshots are in a healthy state, besides the missing database.
- A consolidation would be successful in the VM’s current state if not for the stale locks.
- Consolidation of the VM is failing due to stale locked files. We are getting error: “Inappropriate ioctl for device”
- We checked for a mounted ISO or file but there was no there.
At this point we have a couple of options to try and remediate this issue. Starting with least impactful first.
1) Attempt to Storage VMotion the VM to a different datastore. The hope here is that it will move all active files over to the new datastore which would remove the lock and allow us to consolidate.
–The only problem I see with this is that it might attempt to delete some of the old files after the Svmotion and we will get the same error about files being locked – The hope is that the svmotion would still be successful, it would just fail on the second part (removing the old files) and we could clean that up manually.
2) We can do a rolling reboot of the ESXi hosts in the cluster. This should release and stale locks and allow us to run the consolidation. This is a little more impactful because we have to migrate a lot of VM’s around.
3) As a last resort, we can essentially do a force clone of the vmdk and attach that to the existing VM. This will consolidate the snapshots during the process but would require us to shutdown the VM.
At the end of the day, I used Storage vMotion to move the VM to another datastore, and then I was able to successfully consolidate the virtual machine. After that was completed, I immediately performed a new backup that was successful. Waited 2 days to see if the old files on the previous datastore were being modified (old snapshots) and they weren’t which led me to successfully removing those files to save space.
I hope this helps someone down the road. Thanks for reading!
Thank you, did the trick for me.
helped me
Thank you. Worked for me.
Thank you, this helped me.
Thank you, i meet the problem and fix succsessfully.
Migrating the VM to another datastore (and then consolidating disks) was the ONLY solution that worked for me. Nothing else worked except for this solution (and I tried them all).
Thank you!
Thanks for this post, I don’t typically write stuff but I like your post!
I’ve had this issue a few times <-I've managed 100K+ vms at datacenters.
The trick I use is ssh straight into the ESXI host and restart two services –
/etc/init.d/hostd restart
/etc/init.d/vpxa restart
The GUI may loose connection for a second while it restart. But this will clear lock, since the service has it hung.
After the services restart, you'll be able to consolidate the disks on all the VMs having this issue.
Good Luck!
This worked for me. Thanks for the suggestion, and I’m sure the vmotion storage would have worked too, but I’m glad I didn’t have to do that.
I solved by shutting down the backup server (Veeam Backup). With Veeam off (which is also a VM) it was possible to perform the consolidation in the VM that presented error. After that, I started Veeam Backup.
@Mauricio: Did the exact same thing (BackupExec2015), which also did the trick for me. THX!
Thank you very much, this helped me.
We fixed the issue by clearing stale disks mounted on proxy server. Avamar is used for backup.
java -jar proxycp.jar –listproxydisk –cleanup