
Objective 2.3 – Understand how vSAN Stores & Protects Data
vSAN Protects data in many different forms. We will discuss these in brief.
Storage Policy-Based Management
Storage Policy-Based Management (SPBM) from VMware enables precise control of storage services. Like other storage solutions, vSAN provides services such as availability levels, capacity consumption, and stripe widths for performance. A storage policy contains one or more rules that define service levels.
Storage policies are created and managed using the vSphere Web Client. Policies can be assigned to virtual machines and individual objects such as a virtual disk. Storage policies are easily changed or reassigned if application requirements change. These modifications are performed with no downtime and without the need to migrate virtual machines from one datastore to another. SPBM makes it possible to assign and modify service levels with precision on a per-virtual machine basis.
Failures To Tolerance (FTT): Defines how many failures an object can tolerate before it becomes unavailable.
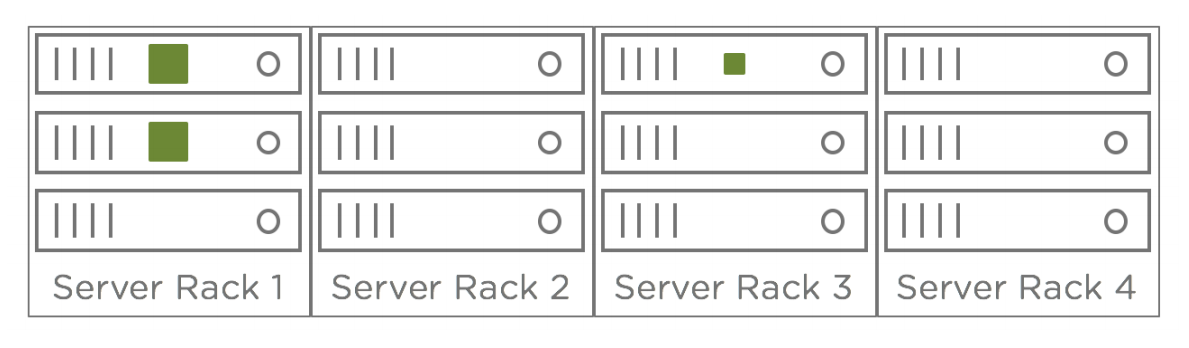
Fault Domains: “Fault domain” is a term that comes up often in availability discussions. In IT, a fault domain usually refers to a group of servers, storage, and/or networking components that would be impacted collectively by an outage. A common example of this is a server rack. If a top-of-rack switch or the power distribution unit for a server rack would fail, it would take all the servers in that rack offline even though the server hardware is functioning properly. That server rack is considered a fault domain.
Each host in a vSAN cluster is an implicit fault domain. vSAN automatically distributes components of a vSAN object across fault domains in a cluster based on the Number of Failures to Tolerate rule in the assigned storage policy. The following diagram shows a simple example of component distribution
across hosts (fault domains). The two larger components are mirrored copies of the object and the smaller component represents the witness component.
vSAN Rack Awareness:
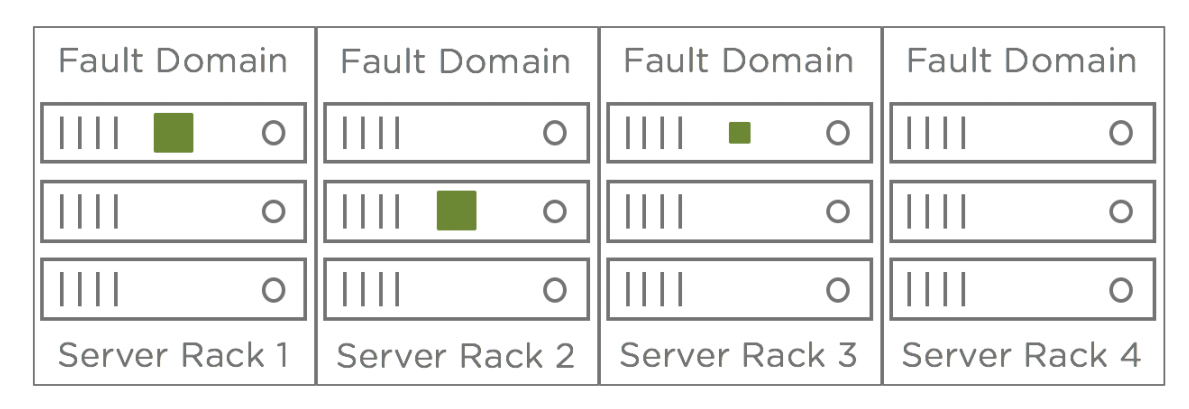
The failure of a disk or entire host can be tolerated in the previous example scenario. However, this does not protect against the failure of larger fault domains such as an entire server rack. Consider out next example, which is a 12-node vSAN cluster. It is possible that multiple components that make up
an object could reside in the same server rack. If there is a rack failure, the object would be offline.
To mitigate this risk, place the servers in a vSAN cluster across server racks and configure a fault domain for each rack in the vSAN UI. This instructs vSAN to distribute components across server racks to eliminate the risk of a rack failure taking multiple objects offline. This feature is commonly referred
to as “Rack Awareness”. The diagram below shows component placement when three servers in each rack are configured as separate vSAN fault domains.
Specific to vSAN 6.6,
It is possible to configure a secondary level of failures to tolerate. This feature enables resiliency within a site, as well as, across sites. For example, RAID-5 erasure coding protects objects within the same site while RAID-1 mirroring protects these same objects across sites.
Rebuild and Re-synchronize:
vSAN achieves high availability and extreme performance through the distribution of data across multiple hosts in a cluster. Data is transmitted between hosts using the vSAN network. There are cases where a significant amount of data must be copied across the vSAN network. One example is when you change the fault tolerance method in a storage policy from RAID-1 mirroring to RAID-5 erasure coding. vSAN copies or “resynchronizes” the mirrored components to a new set of striped components.
2.4 – Describe vSAN Space Efficiency Features
Overview:
Space efficiency features such as:
- Deduplication
- Compression
- Erasure Coding
reduce the total cost of ownership (TCO) of storage which are all features built directly into vSAN. Let’s go into each one a little more in-depth to learn how we’re saving money, storage and increasing performance at the same time.
Deduplication & Compression
Enabling dedup & compression can actually reduce the amount of physical storage consumed by almost as much as 7 times. For example, let’s say you have 20 Windows Server 2012 R2 VM’s and they have all their specific purpose (AD, Exchange, App, Web, DB, etc…). If we didn’t utilize de-dup and compression we would be holding the same set of data 20 times more than we need to.
Environments with redundant data such as similar operating systems typically benefit the most. Likewise, compression offers more favorable results with data that compresses well like text, bitmap, and program files. Data that is already compressed such as certain graphics formats and video files, as well as files that are encrypted, will yield little or no reduction in storage consumption from compression. Deduplication and compression results will vary based on the types of data stored in an all flash vSAN environment.
Note: Dedup and compression is a single cluster-wide setting that is disable by default and can be enabled using a drop down menu in the vSphere Web Client.
RAID 5/6 Erasure Coding
RAID-5/6 erasure coding is a space efficiency feature optimized for all flash configurations. Erasure coding provides the same levels of redundancy as mirroring, but with a reduced capacity requirement. In general, erasure coding is a method of taking data, breaking it into multiple pieces and spreading it across multiple devices, while adding parity data so it may be recreated in the event one of the pieces is corrupted or lost.
Unlike deduplication and compression, which offer variable levels of space efficiency, erasure coding guarantees capacity reduction over a mirroring data protection method at the same failure tolerance level. As an example, let’s consider a 100GB virtual disk. Surviving one disk or host failure requires 2
copies of data at 2x the capacity, i.e., 200GB. If RAID-5 erasure coding is used to protect the object, the 100GB virtual disk will consume 133GB of raw capacity—a 33% reduction in consumed capacity versus RAID-1 mirroring.
RAID-5 erasure coding requires a minimum of four hosts. Let’s look at a simple example of a 100GB virtual disk. When a policy containing a RAID-5 erasure coding rule is assigned to this object, three data components and one parity component are created. To survive the loss of a disk or host (FTT=1),
these components are distributed across four hosts in the cluster.
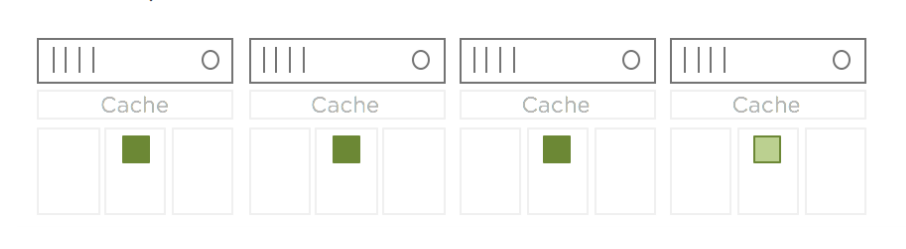
RAID-6 erasure coding requires a minimum of six hosts. Using our previous example of a 100GB virtual disk, the RAID-6 erasure coding rule creates four data components and two parity components. This configuration can survive the loss of two disks or hosts simultaneously (FTT=2)

While erasure coding provides significant capacity savings over mirroring, understand that erasure coding requires additional processing overhead. This is common with any storage platform. Erasure coding is only supported in all flash vSAN configurations. Therefore, the performance impact is negligible in most cases due to the inherent performance of flash devices.
Sparse Swap
- Provision swap objects as thin rather than 100% fully reserved
- Host advanced option enables setting policy for swap to no space reservation
- Used when you are NOT overcommitting on memory
- Available for both All-Flash and Hybrid deployments/configurations
Source: VMware vSAN Technical Doc